Avoiding the NVM Express bottleneck with NVMe CMBs, Eideticom and SPDK
- Written by: Stephen Bates, CTO
On February 14th Eideticom pushed some code into upstream Storage Performance Developers Kit (www.spdk.io and https://github.com/spdk/spdk) that enables new and interesting capabilities related to NVM Express (NVMe) SSDs with Controller Memory Buffers (CMBs). In this article I take a closer look at why we did that and why it’s good for the producers and users of NVMe devices.
NVMe is fast and that’s (mostly) a good thing
NVM Express is fast, I mean it’s really fast. And when I say fast I mean it both in terms of engineering fast (i.e. throughput) and physics fast (i.e. latency). It is easy now to buy NVMe SSDs that can saturate PCIe Gen3x4 (i.e. ~3.2GB/s) and that can service random IO in under 10 microseconds (e.g. Optane or MRAM based NVMe SSDs).
The NVMe Bottleneck
Fast is good right? Well yes it is, but it does introduce new challenges and performance bottlenecks. For example, consider a standard copy of data from one of these fast NVMe SSDs to another. We show what happens in Figure 1.
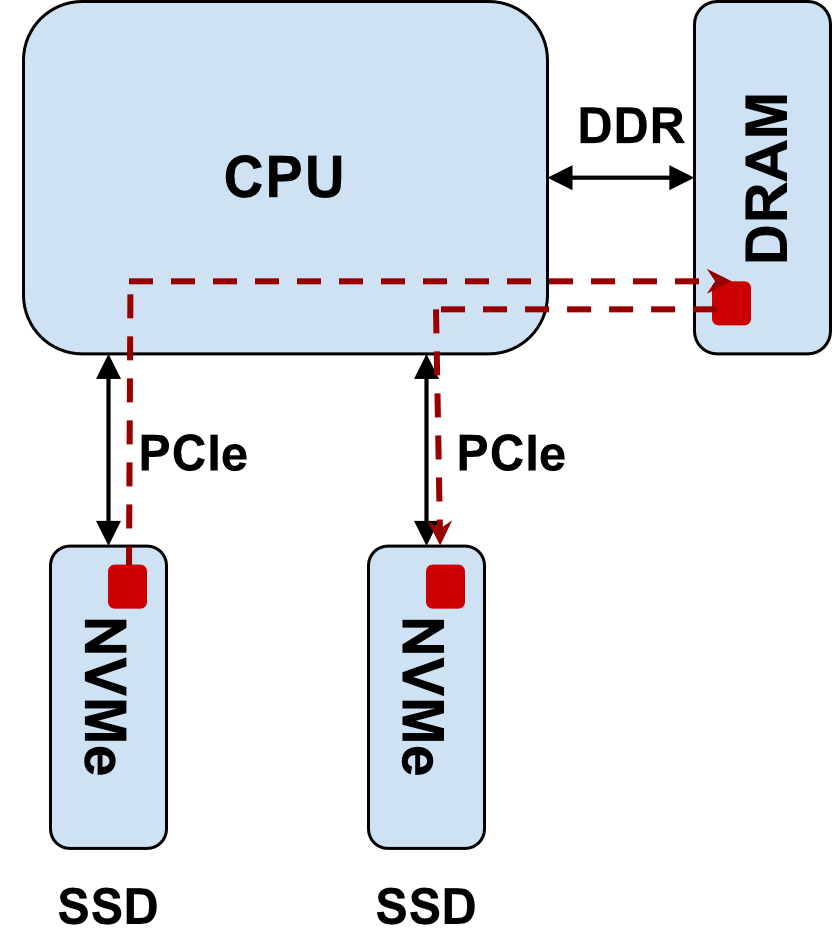
Figure 1: Copying data from NVMe SSD A to NVMe SSD involves following the red dashed line. Data must be DMA’ed by SSD A into CPU DRAM and then DMA’ed by SSD B from CPU DRAM. This places a strain on both the CPU PCIe and memory subsystems.
So you can see that when we want to copy data from SSD A to SSD B that data has to pass through the PCIe and memory subsystem of the CPU, even though the CPU may have no desire to actually look at the data. As we scale the number of SSDs this puts a huge strain on the CPU and becomes the NVMe bottleneck!
Eideticom’s NVMe CMBs to the Rescue!
Why are we using CPU memory for these transfers? It is because the DMA engines in the NVMe SSDs have to have memory locations for their transfers. A DMA engine can’t DMA directly to another DMA engine. So why don’t we give the NVMe SSDs some memory they can use as a DMA target?
Handily enough there is a way to expose such memory on PCIe devices already. It’s called a PCIe Base Address Register (BAR). Even better, the NVMe standard has a way for an NVMe SSD to tell the outside world it has a BAR that can be used for DMA operations and that is the Controller Memory Buffer (CMB). CMBs have been part of the NVMe standard since 2014 but it is only recently that we have started to see NVMe CMBs that support DMA operations. In fact, Eideticom, with its NoLoadTM products, is one of the very first NVMe vendors to provide solutions with this capability.
It’s all about the Software!
However providing NVMe SSDs with CMBs is not enough to bypass the NVMe bottleneck. We need to write software that enables applications to leverage this hardware in interesting ways. That is what we did by pushing support for NVMe CMBs into SPDK, a user-space storage framework from Intel that is now open-source and has a strong emphasis on NVMe and NVMe over Fabrics (NVMe-oF). Now SPDK users can write code that leverages NVMe CMBs and bypasses the NVMe bottleneck. Using this code a new path for NVMe copies has been created!
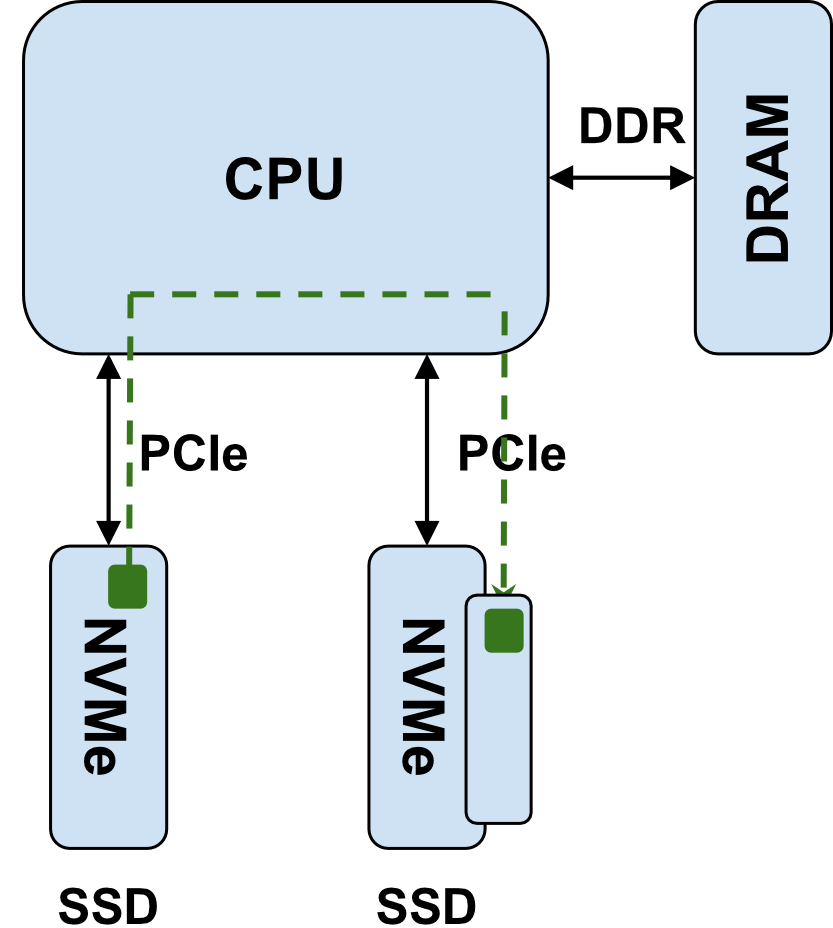
Figure 2: Peer-2-Peer (P2P) copying data from NVMe SSD A to NVMe SSD involves following the green dashed line. Data can now be DMA’ed by SSD A directly into the Controller Memory Buffer (CMB) of NVMe SSD B. This reduces the strain on both the CPU PCIe and memory subsystems. This is the new type of NVMe copy we enabled in SPDK and is demonstrated in the cmb_copy example application we added to SPDK.
As well as adding a new API to allow applications to utilize NVMe CMBs to avoid the NVMe bottleneck we also provide an example application (called cmb_copy) which uses this new API to copy data from one NVMe SSD to another, via the CMB. Check out the code and take a look at the HOWTO below if you want to get started with NVMe CMB enabled copies. We also did a short asciinema demo which you can see here - https://asciinema.org/a/bkd32zDLyKvIq7F8M5BBvdX42.
Where Next?
The SPDK work to date has focused on NVMe to NVMe copies. However the plan is to extend this work to copies between NVMe SSDs and other PCIe devices like RDMA NICs and GPGPUs. Ultimately the goal is to permit copies between many different types of PCIe devices without needing to tax the CPU to do those copies. This will not only remove the NVMe bottleneck but will also remove the PCIe bottleneck!
How do I get Started?
If you want to try this out for yourself then do the following:
- Clone SPDK from https://github.com/spdk/spdk.
- Configure and build SPDK using something like:
- ./configure
- make -j 16
- Run the cmb_copy example application.
- Install two NVMe SSDs, at least one of which has a CMB that supports WDS and RDS (Come see us for that ;-)).
- From your top-level SPDK folder run:
- ./scripts/setup.sh
- Make a note of the pcie addresses of the two NVMe SSDs that should be assigned to UIO (avoid VFIO for now).
- sudo ./examples/nvme/cmb_copy -r <pci id of write ssd>-1-0-1 -w <pci id of write ssd>-1-0-1 -c <pci id of the ssd with cmb>. This should copy a single LBA (LBA 0) from namespace 1 on the read NVMe SSD to LBA 0 on namespace 1 on the write SSD using the CMB as the DMA buffer.